Data Mesh: The 4 Principles of the Distributed Architecture

A data mesh is a decentralised architecture devised by Zhamak Dehghani, director of Next Tech Incubation, principal consultant at Thoughtworks and a member of its technology Advisory Board.
According to Thoughtworks, a data mesh is intended to; “address[es] the common failure modes of the traditional centralised data lake or data platform architecture”, hinging on modern distributed architecture and “self-serve data infrastructure”.
Key uses for a data mesh
Data mesh’s key aim is to enable you to get value from your analytical data and historical facts at scale. You can apply this approach in the case of frequent data landscape change, the proliferation of data sources, and various data transformation and processing cases. It can also be adapted depending on the speed of response to change.
There are a plethora of use cases for it, including:
- Building virtual data catalogues from dispersed sources
- Enabling a straightforward way for developers and DevOps team to run data queries from a wide variety of sources
- Allowing data teams to introduce a universal, domain-agnostic, automated approach to data standardization thanks to data meshes’ self-serve infrastructure-as-a-platform.
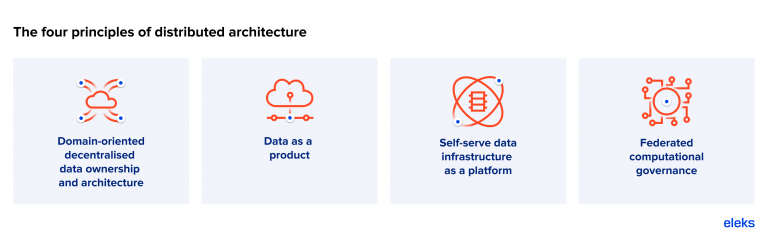
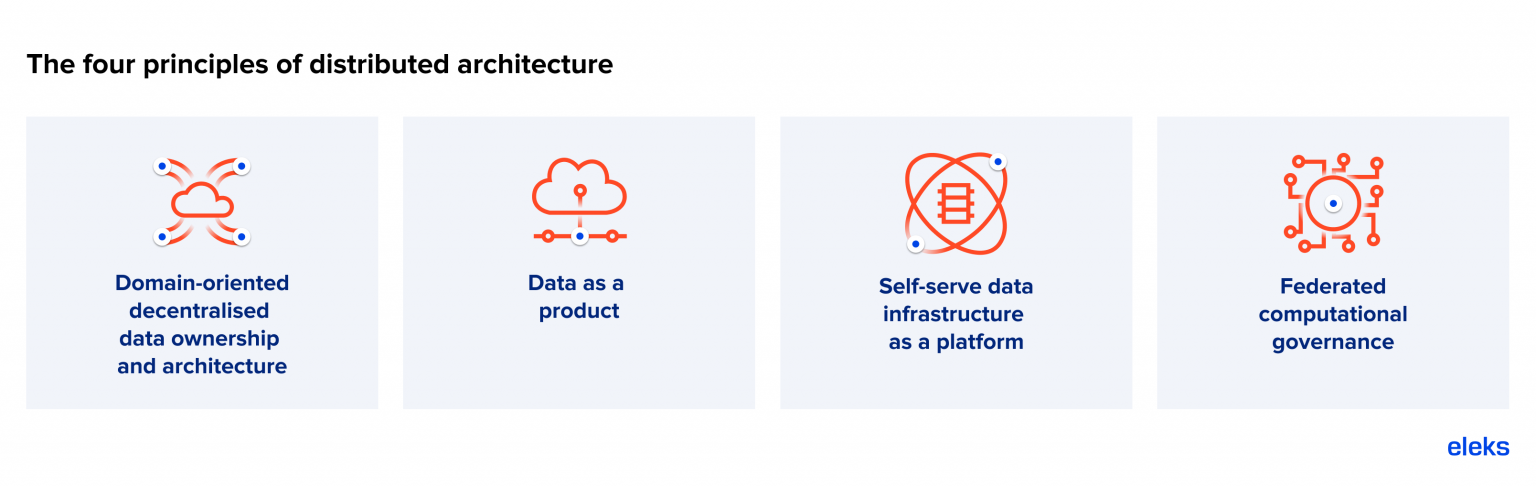
There are four key principles of distributed architecture. Let’s take a look at these in more detail.
Four core principles underpinning distributed architecture
The principles themselves aren’t new. They’ve been used in one form or another for quite some time, and, indeed, ELEKS has used them in various ways for a number of years. However, when applied together, what we get is, as Datameer describes it: “a new architectural paradigm for connecting distributed data sets to enable data analytics at scale”. It allows different business domains to host, share and access datasets in a user-friendly way.
 https://eleks.com/wp-content/uploads/The-four-principles-of-distributed-architecture-1-300×95.png 300w, https://eleks.com/wp-content/uploads/The-four-principles-of-distributed-architecture-1-1024×324.png 1024w, https://eleks.com/wp-content/uploads/The-four-principles-of-distributed-architecture-1-768×243.png 768w, https://eleks.com/wp-content/uploads/The-four-principles-of-distributed-architecture-1-1536×487.png 1536w, https://eleks.com/wp-content/uploads/The-four-principles-of-distributed-architecture-1-2048×649.png 2048w” sizes=”(max-width: 3216px) 100vw, 3216px” />
https://eleks.com/wp-content/uploads/The-four-principles-of-distributed-architecture-1-300×95.png 300w, https://eleks.com/wp-content/uploads/The-four-principles-of-distributed-architecture-1-1024×324.png 1024w, https://eleks.com/wp-content/uploads/The-four-principles-of-distributed-architecture-1-768×243.png 768w, https://eleks.com/wp-content/uploads/The-four-principles-of-distributed-architecture-1-1536×487.png 1536w, https://eleks.com/wp-content/uploads/The-four-principles-of-distributed-architecture-1-2048×649.png 2048w” sizes=”(max-width: 3216px) 100vw, 3216px” />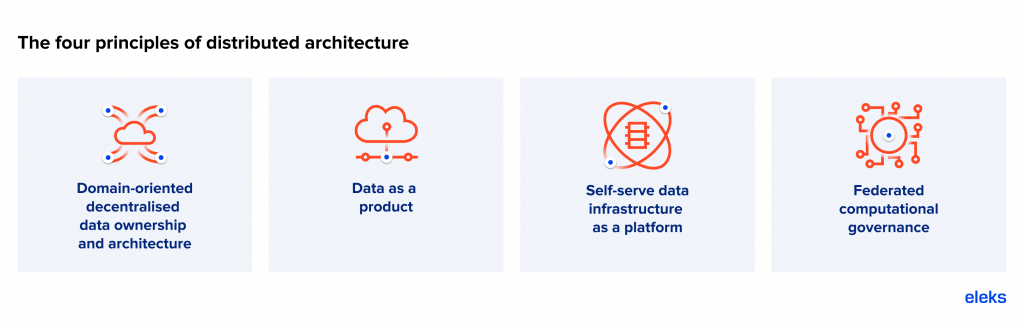{kind=link}
{kind=link}
{kind=link}
{kind=link}